
Imagen satelital de la selva tropical del Amazonas. Imagen: Shutterstock
Nota del editor: Este artículo se publicó originalmente en Notion. Se publica aquí con permiso de los autores.
Esta es la historia de cómo nuestro equipo de periodistas y apasionados de los datos —cuya colaboración surgió a partir de 2021 JournalismAI Collab Challenges— utilizó la inteligencia artificial para realizar una investigación. Nuestra herramienta podría usarse para identificar, por ejemplo, aeronaves ilegales en áreas remotas, la expansión de la deforestación o comprobar si se está construyendo cierta vía pública.
La indicación visual de un cambio específico en el terreno o una infraestructura peculiar vista desde las alturas podrían ser el comienzo de una historia. Si estás investigando e intentando decidir si las imágenes satelitales podrían verificar tus descubrimientos —o para recolectar nueva evidencia y no tienes idea de dónde empezar— esta guía es para ti.
Nuestro equipo (con integrantes de Bloomberg News, CLIP, Data Crítica y La Nación) estaba interesado en explorar el uso de imágenes satelitales con técnicas computacionales aplicadas para la creación de piezas periodísticas. Sabíamos que estas imágenes capturadas por satélites contienen información que podría, potencialmente, aumentar nuestra capacidad para escribir narrativas atractivas sobre el estado de nuestro planeta. Estas herramientas tienden a ser complejas y encontrarse fuera del alcance de muchos periodistas. Así que queríamos crear un flujo de trabajo replicable que pudiera utilizarse para nuevas ideas y proyectos.
En México: Data Crítica obtuvo información sobre la presencia de ganado en áreas protegidas en el sudeste de México. Estas áreas son muy importantes, ya que conforman el bosque húmedo tropical más grande en México y Centroamérica. Este dato fue relevante para obtener imágenes con alta probabilidad de ofrecer información de calidad para entrenar a un algoritmo, el cual podría utilizarse después para detectar áreas similares aplicándolo a nuevas zonas, que en algunos casos habían sido descartadas antes de este ejercicio.
En Colombia: CLIP, junto con su colaborador local 360 y apoyado por el Pulitzer Center on Crisis Reporting, utilizó datos de vacunación de bovinos para identificar una alta densidad de vacas en la frontera de cuatro parques nacionales que son ecosistemas de transición claves para proteger la selva del Amazonas. Para ubicar mejor a las vacas en el mapa, también colaboramos con la Fundación para la Conservación y el Desarrollo Sostenible (Fcds) que posee un amplio conocimiento de campo de estos bosques, ya que las fuentes no siempre concuerdan entre sí respecto a la geografía de estas regiones. La información más actualizada era de 2020. Identificar a las vacas en las imágenes satelitales nos permitiría evaluar la situación actual y establecer si el ganado y la deforestación que conlleva se había seguido expandiendo.
Conseguir, almacenar y procesar las imágenes satelitales
En cuanto fijamos nuestra atención en buscar cualquier indicación de ganadería ilegal dentro de los bosques protegidos del Amazonas, nuestro siguiente paso fue adquirir imágenes que pudieran apoyarnos. Este sería el ingrediente principal para los algoritmos de visión artificial que queríamos probar y entrenar. En un principio, teníamos la ambiciosa meta de enfocarnos en los cuatro países latinoamericanos (México, Colombia, Brasil y Argentina) que cubrían nuestras respectivas organizaciones, pero pronto nos dimos cuenta de que deberíamos reducir nuestras áreas de interés, porque este paso resultó más complicado de lo que habíamos anticipado.
Hoy en día, las fotografías satelitales son más accesibles que nunca, pero conseguir imágenes de alta calidad —las resoluciones que permiten identificar un objeto— tiene un alto coste. Aunque intentamos contactar con los principales proveedores —como Maxar, Planet, Sentinel o Google Earth—, descubrimos que es difícil obtener respuesta a tus consultas cuando estás interesado en una colaboración o un proyecto pequeño. Sin embargo, pronto encontramos que cada vez más programas ofrecen acceso gratuito y/o descargas de imágenes satelitales para organizaciones y periodistas que buscan objetivos específicos, y nos decantamos por ellas.
Utilizamos el programa NICFI de Planet, enfocado en la conservación de la biodiversidad. Estas imágenes tienen una resolución de 4.7 metros por píxel; es más alta que las imágenes Landsat, pero con menos canales.
Dos criterios que debes tener en mente durante esta etapa:
- Costos y disponibilidad de imágenes: el precio depende de la calidad y la calidad depende del tipo de detección que requieras para tu historia. Por ejemplo, en nuestro caso, detectar vacas es una tarea más detallada que encontrar la presencia de parchparcelas en un campo grande. O, en general, anotar las imágenes.
- Almacenar y procesar imágenes: una fotografía satelital de alta calidad requiere al menos 0.3 GB por 100 kilómetros cuadrados. Esto se traduce a alrededor de dos terabytes de imágenes para cubrir un área del tamaño de Texas y hasta 26 terabytes para una de la dimensión de Brasil. Mantener el área limitada te permitirá ser realista respecto a tu capacidad para almacenar y procesar las imágenes. Si queremos realizar algún tipo de detección de cambios (comparando cómo se veía el área hace un año, por ejemplo), esto duplica la capacidad de almacenamiento necesaria.
Comprender las técnicas de IA disponibles
Para alcanzar nuestras conclusiones, encontramos a alguien que ya había intentado desarrollar algoritmos inteligentes para detectar cambios, fenómenos o animales en el terreno por medio de imágenes satelitales. Esto significó:
- Hablar con gente con experiencia y documentar sus técnicas.
- Encontrar una IA o técnica de visión artificial adecuada para procesar las imágenes.
También queríamos hablar con quienes ya hubieran trabajado en proyectos que utilizan imágenes satelitales combinándolas con técnicas de aprendizaje automático.
Lo que aprendimos con nuestras entrevistas e investigación:
- Hay muchas técnicas de IA disponibles para procesar imágenes, descomponer los datos que contienen y crear nuevas asociaciones para encontrar información adicional.
- Por ejemplo, necesitábamos entrenar un algoritmo de identificación de objetos para que identificara el ganado en las imágenes, pero que también usara un análisis de series temporales en múltiples fotografías para encontrar los cambios dentro de las regiones boscosas. Esto aumentó los retos computacionales y nos ayudó a formular un procedimiento técnico en la etapa inicial del prototipo.
- Descubrimos que Texty.org.ua, una agencia de periodismo de datos en Ucrania, había realizado un proyecto similar para Leprosy of the Land, aplicando un modelo automático para detectar la explotación de ámbar con imágenes satelitales y demostrar cómo está creando un paisaje casi lunar en más de 70,000 kilómetros cuadrados. Entrevistamos a Anatoly Bondarenko de Texty.
- También hablamos con Alfredo Kalaitzis del proyecto Counting Cows. (Puedes ver los datos de este proyecto en GitHub).
- Ya que las vacas no son un objetivo estático, cualquier imagen con una definición menor a 0.5 metros por píxel solo nos servía si estaba tomada en nadir (el punto justo debajo del observador). Incluso, 10 grados de inclinación en el ángulo de la imagen afectaría la resolución. Sin embargo, los alrededores pueden revelar la presencia de ganado —con indicadores como vallas, establos, tierra de cultivo o abrevaderos— si el objetivo no es contar las vacas, sino establecer su presencia o ausencia. Esto fue clave para nosotros en From Above, porque, al final, decidimos enfocarnos en los indicadores en lugar de llevar un conteo de las vacas en sí.
- En este caso, las imágenes en alta resolución para su proyecto las obtuvieron gracias a su socio, Global Witness, que se las había comprado a Maxar con fondos recaudados. Puedes pagar para pedir a un satélite que tome fotografías de un área en particular, pero también puedes comprar las licencias para utilizar algunas de las que alguien más ya encargó. A ellos les permitieron publicar su proyecto con capturas de las imágenes originales. A partir de esta recomendación, nuestro equipo buscó a un colaborador que pudiera tener estas fotografías satelitales. La Nación consiguió el financiamiento para comprar una única imagen en alta definición de 0.3 metros por pixel. Declinaron la oferta, porque no era suficiente para usar el algoritmo.
- El proyecto de Kalaitzis cortó las imágenes en recuadros de 100 por 100 para tomar notas. Les llevó algunas horas y requirió más consistencia anotar de manera colectiva. Nosotros seguimos su ejemplo y anotamos de manera grupal. Así encontramos que resultó muy útil para mantener velocidad y coherencia.
- En algunos casos, como el nuestro, almacenar las imágenes no es un gran problema. Cuando estás enfocándote en áreas específicas, puedes ejecutar el proceso que creamos utilizando una PC normal y corriente —con al menos 16 GB de RAM, mientras más RAM mejor— y un disco duro estándar de 1 TB, conforme entrenas y aplicas tus algoritmos a un recuadro (de docenas de kilómetros de extensión) a la vez. Sin embargo, si quisieras almacenar y procesar muchos de estos recuadros satelitales de forma simultánea, o aumentar la escala del proceso de alguna otra manera —por ejemplo, para analizar países enteros—, puede ser necesario utilizar servicios de computación en la nube.
Un interés que teníamos en común era la investigación de la crisis climática desde esta perspectiva, así que comenzamos con el primer, y vital, paso en cualquier historia: las ideas. Reunimos nuestras investigaciones y propusimos diferentes opciones dentro del grupo que podrían extrapolarse utilizando imágenes de bosques, litorales y otros elementos geográficos; delimitamos el objetivo a identificar ganadería ilegal en la frontera de bosques protegidos.
“Creemos que el mayor factor limitante para estas aplicaciones es el acceso a imágenes en alta resolución y no así el desarrollo de los algoritmos de conteo. Además, la identificación de un individuo específico requiere resoluciones que aún no están disponibles en los satélites comerciales” —Alfredo Kalaitzis del proyecto Counting Cows.

Área de interés en el bosque húmedo tropical mexicano. Imagen: cortesía del equipo de From Above
Enfocando nuestros esfuerzos
A pesar de haber intentado ponernos en contacto con los mayores proveedores de imágenes satelitales, encontramos difícil que respondieran a consultas para colaboraciones o proyectos pequeños. Pero pronto descubrimos que hay un creciente número de programas que ofrecen acceso gratuito y/o descargas de imágenes satelitales para organizaciones y periodistas con algunas metas específicas y redirigimos nuestros esfuerzos hacia esas fuentes.
El tema es que si no podíamos acceder a imágenes HD de hasta 0.4 metros por píxel, nos sería imposible detectar a las vacas.
“Esperemos que al menos podamos obtener [imágenes] de alguno de los países y ver cómo se ejecuta el proceso entero. Si eso no es posible, podemos cambiar nuestra investigación y enfocarla en la detección de objetos más grandes, para poder utilizar las imágenes gratuitas disponibles”. —Flor Coelho, integrante del equipo From Above.
Decidimos desarrollar el planteamiento enfocado en el uso de la tierra que habíamos discutido en las etapas iniciales de la colaboración. Identificaríamos la ganadería utilizando imágenes de menor resolución que las necesarias para detectar al ganado. Investigamos cómo los lentes RGB —rojo, verde y azul— y lentes infrarrojos nos permitirían analizar la detección de objetos. Los satélites pueden utilizar lentes RGB o infrarrojos para identificar mejor diferentes cosas.
Con esta información, nos concentramos en desarrollar una herramienta que nos permitiera detectar ganado (bovino) en áreas que estuvieran protegidas o que anteriormente estuviesen cubiertas por bosques en Argentina, Brasil, Colombia y México.
También decidimos utilizar el programa NICFI de Planet.
Una vez que tienes una cuenta de NICFI en Planet observas la diferencia entre Planet’s Basemaps Viewer y Planet’s Explorer. El primero te permite descargar imágenes “analíticas”, con las muchas capas mencionadas anteriormente. Ya en Basemap (o cualquier otra fuente de imágenes satelitales) deberías poder distinguir con claridad entre los compuestos “visuales” descargables y los “analíticos”. El segundo grupo está codificado con las diferentes bandas a las que nos hemos referido antes. Visualmente, Explorer y Basemaps lucen casi idénticos, pero solo el segundo te permite descargar las imágenes para su procesamiento y extracción/modelado de datos.
Criterios de anotación y guías
Decidimos recolectar etiquetas para la función de segmentación de imágenes y elegimos una herramienta (GroundWork), que se adaptaba a las preferencias de trabajo de nuestro equipo, al balancear el reto que suponían las restricciones de datos y tiempo. También fue importante para nosotros establecer y acordar las guías según las cuales anotaríamos las imágenes para nuestra Área de Interés (AOI, por sus siglas en inglés).

Imágenes: cortesía del equipo de From Above

Puedes utilizar la composición visual (la que tiene menos capas) para hacer tus anotaciones. Lo que obtienes después del proceso son polígonos o puntos que dibujas para cada elemento que intentas identificar en el terreno (y sus referencias de latitud y longitud). Más adelante, relacionarás esa información con la reflejada en las imágenes satelitales codificadas.
Deberías elegir una herramienta de anotación, con base en las ventajas y desventajas que presenten para tu misión específica. Existen muy buenas opciones en línea, como OpenCV o Cvat, aunque no pudimos probarlas a profundidad.
Por ejemplo, algunas herramientas permiten una colaboración digital fluida, pero puede que te impidan subir imágenes en una resolución mayor a las fotos de Planet (4.7 metros por pixel). En ese caso, puedes utilizar un proceso sin conexión, con programas como QGIS o R en tu propio sistema computacional.
Sin embargo, nosotros queríamos realizar las anotaciones de manera colectiva para asegurar consistencia y velocidad, y trabajar sin conexión habría complicado la colaboración.
Decidimos utilizar GroundWork, con el cual es fácil realizar anotaciones colectivas.
Los expertos en periodismo de fuente abierta, Bellingcat, colaboraron con nosotros y no solo nos ofrecieron capacitación para utilizar las herramientas de Planet, sino que nos dieron algunas imágenes en muy alta resolución de un área de los parques donde estábamos identificando vacas en Colombia. Estas imágenes provenían de trabajos anteriores de Planet, a los que Bellingcat tenía acceso gracias a su cuenta de paga.
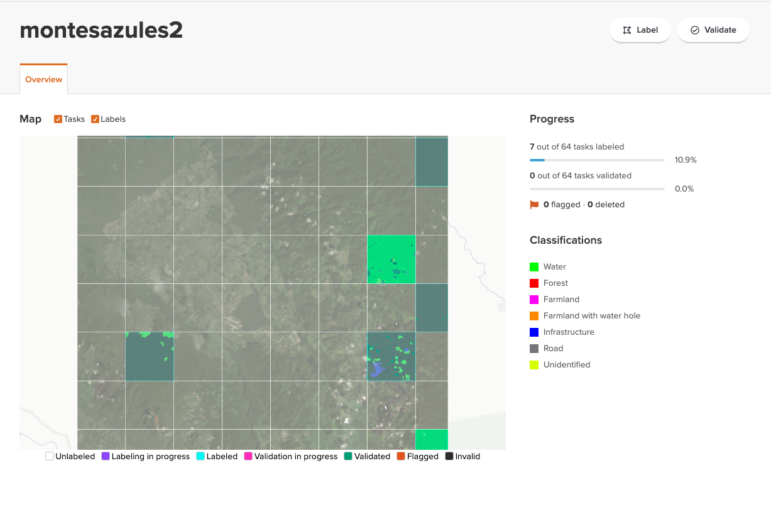
El equipo de From Above eligió identificar siete diferentes clasificaciones de terreno, mientras estudiaban sus áreas de interés. Imagen: cortesía del equipo de From Above
Elegimos siete etiquetas (agua, bosque, terreno agrícola, terreno agrícola con pozo de agua, infraestructura, camino y no identificado) para usar en nuestro algoritmo supervisado.
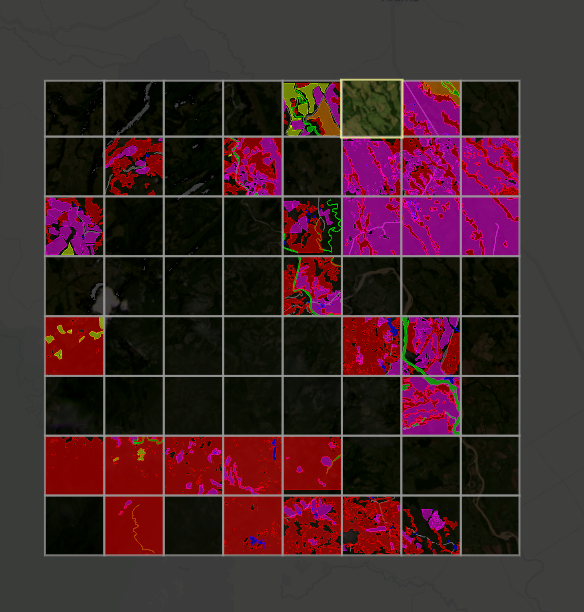
El equipo de From Above eligió identificar siete diferentes clasificaciones de terreno, mientras estudiaban sus áreas de interés. Imagen: cortesía del equipo de From Above
Esta imagen se dividió en cuadrantes más pequeños que se anotaron cuadrícula por cuadrícula. Las coloreadas ya están anotadas, pero el resto seguían sin etiquetarse cuando se realizó esta captura de pantalla.
Por ejemplo, Bellingcat nos dio algunas imágenes en muy alta resolución que nosotros no podíamos subir a GroundWork, debido a una falla técnica de la aplicación. Esto nos forzó a verificar con frecuencia cada anotación usando un mapa de alta resolución disponible en línea, como Google Earth.
Pasamos alrededor de tres horas anotando juntos y otras 15 de manera individual, luego que acordamos cuáles serían las etiquetas útiles y establecimos algo de consistencia en aquello que calificaba como bosque, agua, terreno agrícola, entre otros. Realizamos anotaciones en cada cuadrícula de cuatro imágenes: dos de parques colombianos y dos de la reserva mexicana.
Paso a paso: proceso de segmentación
Teníamos dos tipos esenciales de datos con los cuales trabajar:
- Imagen satelital original — información de las capas de la imagen rasterizada (en formato TIFF).
- Imagen anotada — datos etiquetados con el proceso de anotación (en formato de archivo GeoJSON).

En este arreglo, puedes ver la imagen analítica descargada en cinco capas: roja, verde, azul, infrarroja y una capa “alfa” adicional. Algunos programas, como este, generan estos distintos colores en una escala de grises. Imagen: cortesía del equipo de From Above
Los siguientes pasos nos ayudaron a extraer la información visible al ojo humano, aprender las asociaciones entre capas y crear etiquetas para construir nuestro prototipo inicial:
- Extrae información incrustada en las capas (bandas) de las imágenes satelitales. Diferentes arreglos de capas representan la información de manera distinta. La primera imagen es una composición con los “colores reales” que puede percibir el ojo; a la derecha, una combinación de rojos y casi infrarrojos que resalta la vegetación (en rojo).
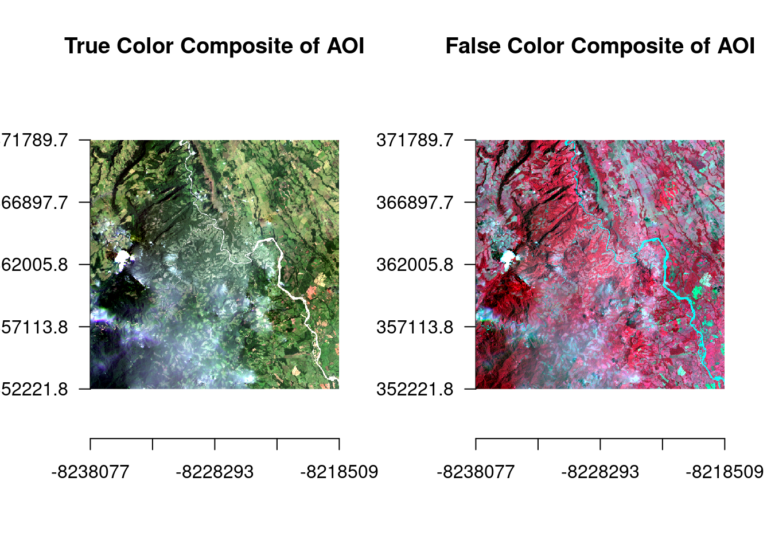
Imagen: cortesía del equipo de From Above
- Extrae la información de la imagen etiquetada:
- Crea un conjunto de datos basado en una inspección visual y de conocimiento contextual del área (es decir, haz anotaciones en la imagen).
-
- Asegúrate de que el conjunto de datos anotados y la imagen satelital son compatibles en términos de extensión, proyección de sistemas de referencia y resolución. En este caso, habíamos tomado notas sobre la misma imagen así que teníamos archivos compatibles, pero es posible que, por ejemplo, la herramienta de anotación añada o elimine información de la imagen original, así que esto sirve para asegurarte de tener todos los elementos necesarios.
- Extensión: la latitud y longitud tienen que ser iguales a la forma de ambos archivos.
- Proyección de sistema: deberían tener el mismo sistema de coordenadas de referencia.
- Asegúrate de que el conjunto de datos anotados y la imagen satelital son compatibles en términos de extensión, proyección de sistemas de referencia y resolución. En este caso, habíamos tomado notas sobre la misma imagen así que teníamos archivos compatibles, pero es posible que, por ejemplo, la herramienta de anotación añada o elimine información de la imagen original, así que esto sirve para asegurarte de tener todos los elementos necesarios.
- Resolución: deberían tener la misma resolución de metros por píxel.
- Fusiona la información satelital y las anotaciones juntas. En lo que se conoce como un modelo “supervisado” de entrenamiento, tú provees las clasificaciones que estás haciendo que el aprenda sistema de manera deliberada. En un método “no supervisado”, dejas que la computadora detecte de forma automática el número de clasificaciones que tú decidas. Esto puede ser más rápido que anotar la imagen, pero podrías perder información contextual crucial que solo es capaz de percibir el ojo humano.
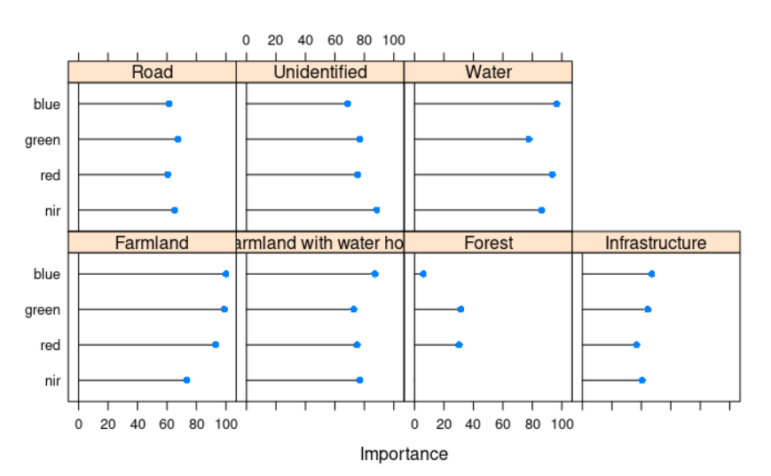
Imagen: cortesía del equipo de From Above
- Pídele al programa que aprenda las asociaciones inherentes entre las capas de información (entrena al algoritmo). Puedes elegir de entre diferentes métodos de aprendizaje asociativo. Por ejemplo, nosotros nos inclinamos por el algoritmo Random Forest, pero también podríamos haber utilizado Supervised Vector Machines o cualquier otro.
- Las asociaciones entre categorías e información inherente están codificadas en los píxeles de cada capa de la imagen satelital. Por ejemplo, la fuerza de las asociaciones entre nuestro trabajo de clasificación y cada capa está desarrollado a continuación. Hay algunas capas de información que van a funcionar mejor que otras para predecir categorías específicas de tu clasificación.
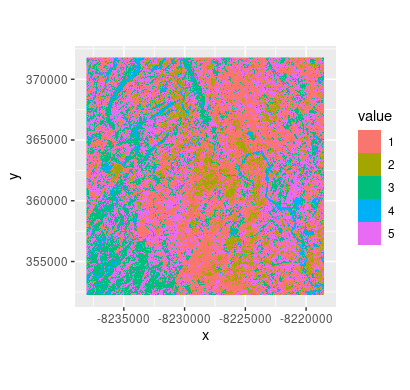
El resultado final del algoritmo de segmentación de imágenes. Imagen: cortesía del equipo de From Above
- Pruébalo con nuevos datos satelitales. Idealmente, ahora habrás identificado alguna información visual interesante con las imágenes y las técnicas computacionales para respaldar tu historia o generar un periodismo de mayor profundidad.
Existe una versión detallada del desarrollo de estos pasos en el archivo de From Above para permitir que se reproduzca en su totalidad en GitHub, aquí o aquí.
Recursos:
Esta es una compilación de los recursos que nos beneficiaron y que recomendamos a otros:
- Fuentes de datos
-
-
- Planet API
- Planet NICFI
- Puedes encontrar información digital en la nueva agencia de noticias de Maxar, la nueva sección de Planet y en Skytruth, que también realiza crónicas de sus proyectos. Está también Descartes Lab. Además, intentamos contactar al proyecto MAAP para conseguir imágenes de la selva tropical del Amazonas, basadas en fotos de Sentinel, financiado por el gobierno de Noruega.
-
- Historias y publicaciones que nos inspiraron:
-
- Contando elefantes con Worldview 3 de Maxar (Oxford). Leímos su ensayo de investigación sobre el conteo de elefantes para buscar posibles sinergías.
- Datatón de WiDS para detectar plantaciones de aceite de palma. (Stanford).
- Detección de basura de fuente abierta.
- Enlace al ensayo de investigación académica sobre la calidad de imagen necesaria para contar vacas.
Recursos adicionales:
Interpretar datos: consejos para evitar errores y entender los números
Cómo un equipo de datos mexicano descubrió la historia de 4,000 mujeres desaparecidas
El equipo de From Above está conformado por cinco periodistas de datos (provenientes de América del norte y del sur). Ellos se unieron en una colaboración de Periodismo con IA organizada por POLIS, un centro de investigación del London School of Economics. Se enfocaron en investigar la crisis climática por medio de la observación, utilizando imágenes satelitales y experimentaron con técnicas de visión computacional. Publicaron una guía y el prototipo de fuente abierta correspondiente (en Github) con la esperanza de que sirva como base para hacer periodismo de mayor profundidad. Los integrantes del equipo y los enlaces a sus biografías son los siguientes:
- María Teresa Ronderos de CLIP (en Colombia)
- Flor Coelho de LaNacion (en Argentina)
- Gibran Mena de Data Crítica (en México)
- David Ingold y Shreya Vaidyanathan de Bloomberg News (en Estados Unidos)
