ছবি: শাটারস্টক
পল ব্রাডশের দেওয়া এই পোস্ট মূলত অনলাইন জার্নালিজম ব্লগে প্রকাশিত হয়েছিল এবং অনুমতি নিয়ে এখানে পুনরায় প্রকাশ করা হলো। ব্রাডশ বার্মিংহাম সিটি ইউনিভার্সিটিতে ডেটা সাংবাদিকতার স্নাতকোত্তর কোর্স পরিচালনা করেন।
ডেটা সাংবাদিকতা পড়াতে ও শেখাতে গিয়ে আমি প্রায়ই ডেটাসেট থেকে পাওয়া স্টোরির অতিপ্রচলিত ধরন নিয়ে কথা বলি। তাই ভাবলাম, ডেটা সাংবাদিকতার ১০০টি প্রতিবেদন নিয়ে বিশ্লেষণ করে দেখি যে কোন কোন অ্যাঙ্গেল কত বেশি ব্যবহার হয়৷
বিশ্লেষণ করে দেখলাম, আসলে মোটাদাগে ডেটাভিত্তিক স্টোরির সাতটি মৌলিক অ্যাঙ্গেল আছে। অনেকে স্টোরিটেলিংয়ে দ্বিতীয় মাত্রা হিসেবে অন্যান্য অ্যাঙ্গেলগুলোকে যুক্ত করেন (যেমন, সংখ্যাগত পরিবর্তন বিষয়ক প্রতিবেদনে এক পর্যায়ে কোনো কিছুর স্কেল বা আকারসূচক বিশ্লেষণও যুক্ত হতে পারে), তবে আমার দেখা ডেটা স্টোরিগুলোতে এই সাতটি অ্যাঙ্গেল থেকে কোনো না কোনো একটিকে প্রধান হিসেবে বেছে নেওয়া হয়েছে।
দুই-পর্বের এই ধারাবাহিকের প্রথমটিতে আমি দেখিয়েছি, চারটি সাধারণ অ্যাঙ্গেল কীভাবে আপনাকে স্টোরির আইডিয়া বা ধারণা, সেগুলো বিভিন্নভাবে বাস্তবায়ন ও মনে রাখার মতো বিবেচ্য বিষয়গুলো চিনতে সহায়তা করতে পারে।
ডেটা অ্যাঙ্গেল ১: স্কেল – ‘সমস্যাটি আসলে এত বড়’
সম্ভবত ডেটা থেকে সবচেয়ে বেশি পাওয়া যায়, স্কেল বা আকার বিষয়ক স্টোরি: এই স্টোরিগুলো একটি বড় সমস্যা বা প্রাসঙ্গিক হয়ে ওঠা একটি সমস্যার আকার চিহ্নিত করে।
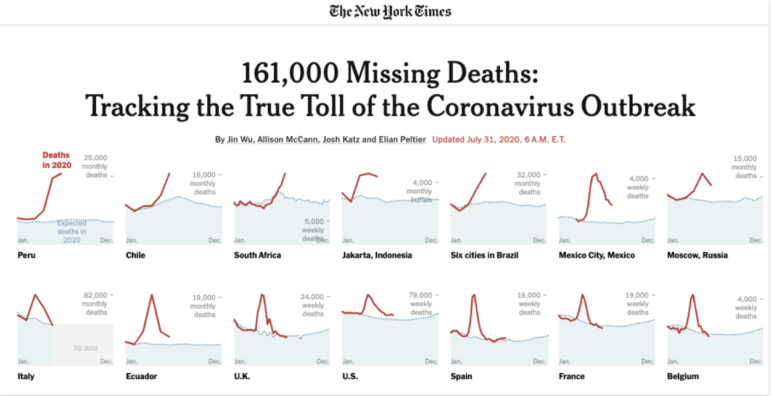
ছবি: স্ক্রিনশট, নিউ ইয়র্ক টাইমস
সবচেয়ে সহজ স্কেল বিষয়ক স্টোরিগুলোতে নতুন বা সর্বশেষ প্রকাশিত সংখ্যার আপডেট দেওয়া হয়: এটি হতে পারে বেকারত্ব, অপরাধের পরিমাণ, বায়ু দূষণ, এলাকাভিত্তিক অর্থ ব্যয়, অথবা জন্ম, মৃত্যু বা বিয়ের সর্বশেষ পরিসংখ্যান।
যেমন, আমরা মহামারির প্রথম কয়েক মাসে মামলা, মৃত্যু ও স্বাস্থ্য-পরীক্ষার সংখ্যা নিয়ে প্রায় প্রতিদিনই স্কেল বিষয়ক স্টোরি হতে দেখেছি।
যুক্তরাজ্যে সেবা সদনগুলোতে করোনা ভাইরাসে আক্রান্ত মৃতের সংখ্যা জরিপের তথ্যমতে ৬,০০০ হতে পারে, এবং অসঙ্গতভাবে প্রদান করা স্বল্পমেয়াদী সাজা পর্যালোচনার পদ্ধতিটি ‘অপ্রতুল’ শিরোনামের প্রতিবেদন দুটি স্কেল স্টোরির অন্যতম উদাহরণ, যেখানে মূল ভিত্তি ছিল প্রতিবেদকের চিহ্নিত করা একটি সমস্যার স্কেল বা আকারের প্রতিক্রিয়া।
অনেক সময় দিনের ঘটনা নিয়ে করা স্টোরির পটভূমি হিসেবে স্কেল ব্যবহার করা হয়, যেমন ড্রোনের কারণে গাটউইক এয়ারপোর্টে বিঘ্ন ঘটে (কতবার অল্পের জন্য বিঘ্ন ঘটেনি?) বা কোনো নীতি-প্রস্তাবের পটভূমিতে স্কেল থাকে, যেমন মন্ত্রীদের মতে, নতুন ড্রাইভারদের জন্য রাতে গাড়ি চালানো নিষিদ্ধ হতে পারে, (কতজন নতুন ড্রাইভারের বয়স ১৯ বছরের কম?)।
সহজে লেখা যায়, এমন স্টোরিগুলোর মধ্যে স্কেল বিষয়ক স্টোরি অন্যতম, যেখানে অনেক ক্ষেত্রে কোন হিসাবনিকাশের প্রয়োজন হয় না।
প্রকৃতপক্ষে, মূল কাজটি হলো সেই স্কেলের প্রেক্ষাপট নির্ধারণ করা — সবচেয়ে বাজে ধরনের স্কেল বিষয়ক স্টোরিগুলো নিছক “বড় সংখ্যার” স্টোরিতে রূপ নেয় (“বেশ কিছু বিষয়ে অনেক টাকা খরচ হয়েছিল” বা “অনেক মানুষের সঙ্গে কিছু একটা ঘটেছে”)। তখন পাঠক বুঝতে পারে না যে আসলেই বিষয়টি সংবাদ হওয়ার মতো, নাকি নেহাতই স্বাভাবিক ঘটনা।
তাই যে কোনো ঘটনায় শতাংশ বা অনুপাত (যেমন “পাঁচের মধ্যে একজন”) বা তুলনা ও উপমা ব্যবহার করাটা গুরুত্বপূর্ণ (“কোনো ঘটনায় খরচ হওয়া অর্থ ৫০০ শিক্ষকের মজুরির সমান”)।
আপনি একটি কম গুরুত্বপূর্ণ অ্যাঙ্গেল হিসেবে পরিবর্তন এবং/অথবা পার্থক্য টেনে আনতে পারেন: এর অর্থ হচ্ছে আপনার দেওয়া স্কেলের ঐতিহাসিক প্রেক্ষাপট, বা স্কেলে পার্থক্য কীভাবে হচ্ছে সেটি তুলে ধরা।
যেমন, নিউইয়র্ক টাইমসের উপরের লেখাটিতে পাঠক চার্ট দেখেই বুঝতে পারবে, করোনাভাইরাস মহামারিতে “নিহতের সত্যিকারের সংখ্যার” (স্কেল) প্রেক্ষাপটটি কেমন ছিল। এতে দেখা যায়, বছরের শুরু থেকে দেশটির বিভিন্ন অঞ্চলে কীভাবে পরিস্থিতির পরিবর্তন হয়েছে।
ডেটা অ্যাঙ্গেল ২: পরিবর্তন ও স্থবিরতা – বাড়ছে, কমছে, অনড়

ছবি: স্ক্রিনশট, বেলফাস্ট টেলিগ্রাফ
চেঞ্জ বা পরিবর্তন বিষয়ক স্টোরিগুলো স্কেল স্টোরির মতোই বহুল ব্যবহৃত — এবং সম্ভবত পিচ করাও সহজ।
পরিবর্তন, স্বাভাবিকভাবেই একটি সংবাদযোগ্য বিষয় এবং এটি শিরোনাম তৈরির জন্য প্রয়োজনীয় ক্রিয়াপদের (“ওঠে,” “নামে,” “[বেড়ে] যায়”) যোগান দেয়।
যখন আপনি ডেটায় কোনো পরিবর্তন লক্ষ্য করবেন, তখন “কেন” সেটি হচ্ছে তার উত্তর খুঁজতে আপনাকে আরো আরও কাজ করতে হবে। কেন এই সংখ্যা বাড়ছে বা কমছে?
আপনার গল্পে ছোটখাটো একটি অ্যাঙ্গেলও জুড়ে দিতে পারেন যা সেই প্রবণতায় ব্যতিক্রমী কিছু সামনে আনবে – যে যে অঞ্চলে বেড়েছে বা কমেছে, কোথায় বৃদ্ধি সবচেয়ে বেশি এবং কোথায় সবচেয়ে কম।
এটি আপনার রিপোর্টিংকে “কেন?” প্রশ্নের দিকে পথ দেখাতে সহায়তা করতে পারে। কারণ এমন সম্ভাবনাও উড়িয়ে দেওয়া যায় না যে সবচেয়ে বেশি আক্রান্ত এলাকাগুলো এই সমস্যা সম্পর্কে সচেতন এবং সেখানকার অধিবাসীরা বিষয়টি নিয়ে কথা বলতে পারে।
পরিবর্তন নিয়ে প্রতিবেদনের সময় দুটি বিষয় বিবেচনা করা জরুরি: সিজনালিটি (সময়ের বৈশিষ্ট্য) এবং মার্জিন অব এরর (ভুলের মাত্রা)।
সিজনালিটি হলো এমন একটি বিষয় যেখানে (সাধারণত অনুমানযোগ্য ও স্বাভাবিক, আর তাই অ-সংবাদযোগ্য) মৌসুমী বিষয়গুলো সংখ্যায় প্রকাশ পেতে পারে, যেমন একটি অর্থ বছর বা স্কুলের মেয়াদ শেষ হওয়া, নতুন গাড়ি উন্মোচন বা কেবলমাত্র তাপমাত্রার পরিবর্তন। প্রায়ই সিজনালিটির প্রভাব প্রতিরোধে সালওয়ারী তুলনা (যেমন, গত বছরের আগস্টের তুলনায় এই আগস্ট) বা কালভিত্তিক সমন্বয় ব্যবহৃত হয়।
এদিকে, মার্জিন অব এরর হলো সেই পরিসর যেখানে প্রকৃত সংখ্যাগুলো আসলে ভুল তথ্য উপস্থাপন করে৷ অনেক ডেটাসেট নমুনার ভিত্তিতে তৈরি হওয়ায় পরবর্তীতে বাদবাকি সব উপাত্তে নজর দিয়ে সাধারণীকরণ করা হয়, সেই সাধারণীকরণটি আসলে কতটা সঠিক তা বোঝাতে ভুলের মাত্রা (বা কনফিডেন্স ইন্টারভাল) ব্যবহার করা হয়। সেই ভুলের মাত্রায় কোনো পরিবর্তন পেলে, তখন আসলে কোনো পরিবর্তন হয়েছে বলে রিপোর্ট করা যায় না।
পরিবর্তন না হওয়াও পরিবর্তন বিষয়ক স্টোরির একটি ভিন্ন অ্যাঙ্গেল। যেমন, কোম্পানির অস্বচ্ছলতা নিয়ে এই স্টোরিটি মানুষের প্রত্যাশার জায়গায় একটি পরিবর্তন খোঁজ করেছে। আপনি হয়ত আশা করছেন যে মহামারিতে অনেক কোম্পানি লোকসানে ডুবে যাবে, কিন্তু উল্টো দেখা গেছে, মহামারির সময় দেউলিয়া কোম্পানির সংখ্যা বাড়েনি। প্রত্যাশার বিপরীতে ডুবে যাওয়া কোম্পানির সংখ্যা কেন বাড়ল না, তার উত্তর জানতে এই প্রতিবেদনে বিশেষজ্ঞদের মন্তব্য জানতে চাওয়া হয়েছে।
ডেটা অ্যাঙ্গেল ৩: র্যাঙ্কিং (তালিকা) ও আউটলায়ার (ব্যতিক্রম) – কে উৎকৃষ্ট, কে নিকৃষ্ট? কে অস্বাভাবিক আর এর কারণ কী?
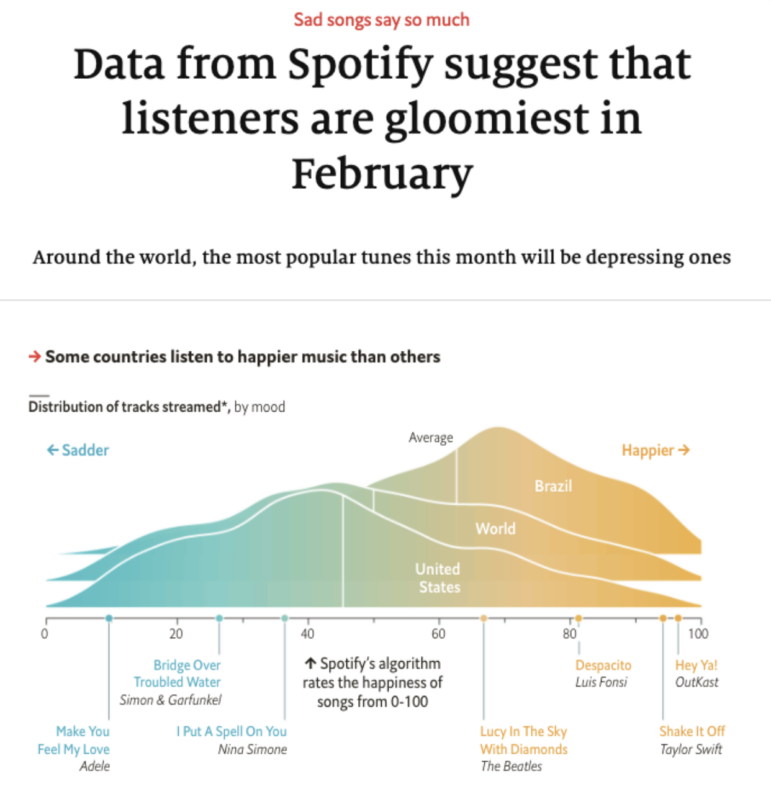
দ্য ইকোনমিস্টের এই নিবন্ধটি “র্যাঙ্কিং” বিষয়ক স্টোরি কারণ এখানে “সবচেয়ে দুঃখের” মাসটিকে চিহ্নিত করা হয়৷ ছবি: স্ক্রিনশট, দ্য ইকোনমিস্ট
র্যাঙ্কিং বিষয়ক স্টোরিগুলো হলো ডেটাসেটে কে বা কী সবচেয়ে খারাপ বা সেরা, বা কোনো নির্দিষ্ট প্রতিষ্ঠান (স্থানীয় পুলিশ বাহিনী, স্কুল বা দল, অথবা বিশেষ বিষয়ে বিশেষজ্ঞতাসম্পন্ন কোনো গণামাধ্যম হলে একটি ইন্ডাস্ট্রি) অন্য প্রতিষ্ঠানের তুলনায় কেমন করছে।
“এই এলাকাটি সবচেয়ে অপরাধপ্রবণ” বা “স্থানীয় স্কুলের শিক্ষার্থীরা পরীক্ষার ফলাফলে সেরাদের মধ্যে তৃতীয় হয়েছে” – এমন স্টোরি এই ক্যাটাগরিতে সবচেয়ে বেশি দেখা যায়।
আপনি নজর দিতে পারেন সবচেয়ে বেশি আক্রান্ত এলাকার দিকেও। যেমন: ইউনিভার্সাল ক্রেডিট অ্যাডভান্সেস (এক ধরনের ঋণ) এর কারণে যুক্তরাজ্যে সবচেয়ে বেশি আক্রান্ত ১০টি এলাকার তালিকায় বার্মিংহামের একাংশ। আপনি দেখতে চাইতে পারেন যে কোন নির্দিষ্ট খাত, অন্য খাতের তুলনায় কেমন করছে। যেমন. নির্মাণখাত যুক্তরাজ্যের সবচেয়ে বিপজ্জনক শিল্পের মধ্যে তৃতীয়।
তবে র্যাঙ্কিং ঘরানার স্টোরিগুলো সবচেয়ে সেরা বা সবচেয়ে খারাপ সময়, স্থান বা বিভাগ নিয়েও হতে পারে,” যা ডেটাসেট থেকে “বেরিয়ে আসতে পারে।”
যেমন, ইকোনমিস্টের উল্লিখিত নিবন্ধটির বিষয়বস্তু ছিল কোন মাসে সবচেয়ে বেশি দুঃখের গান শোনা হয়। অন্যদিকে বার্মিংহাম লাইভের এই স্টোরিতে তুলে ধরা হয় স্যান্ডওয়েলে কোন অপরাধ বেশি ঘটে — এবং কোথায় আপনার অপরাধের শিকার হওয়ার আশঙ্কা বেশি।
দ্য ইকোনমিস্টের ডেটা সাংবাদিকতার নিউজলেটারে “কীভাবে একটি সূচক সংকলন করা যায়” শিরোনামে একটি নির্দিষ্ট অংশ রয়েছে:
“এ ধরনের সূচকগুলো কতটা দরকারি? বস্তুনিষ্ঠ মাপকাঠি না থাকলে যে কোনো র্যাঙ্কিং নিয়ে সমালোচনা হতে পারে। গুণগত র্যাঙ্কিংগুলোর পরিমাপ আপেক্ষিক হয়ে থাকে। সম্ভবত কারো কাছে যা ‘সহনীয়’ অন্য কারো কাছে তাই ‘অস্বস্তিকর’ হতে পারে- যেখানে ‘অনাকাঙ্খিত’ বিষয়ের চেয়ে ‘অসহনীয়’ দ্বিগুণ খারাপ মনে হতে পারে? অর্ডিনাল স্কেলে (যেখানে সূচক পর্যায়ক্রমে দেখানো হয়) একটি সূচক থেকে অন্যটির মধ্যবর্তী দূরত্বটি আপেক্ষিক – এরপরও এই র্যাঙ্কিং কাজে লাগাতে সেগুলোতে একটি সংখ্যাসূচক স্কোর আরোপ করতে হবে।
“দ্য ইকোনমিস্ট ১৯৮৬ সাল মুদ্রার মানের পরিসংখ্যান তুলে ধরে বিগ ম্যাক সূচক প্রকাশ করে আসছে। ২০১১ সালে আমরা শু থ্রোয়ার্স ইনডেক্স প্রকাশ করেছি, যেখানে আরব বিশ্বজুড়ে অস্থিরতার সম্ভাবনা মূল্যায়ন করা হয়েছে। আর এ বছর আমরা একটি বৈশ্বিক স্বাভাবিকতা সূচক তৈরি করেছি, যা কোভিড-১৯ এর প্রভাব কাটিয়ে দেশগুলোর ঘুরে দাঁড়ানো ট্র্যাক করছে। একেবারেই কোনো তুলনামূলক চিত্র উপস্থপানের ব্যবস্থা না থাকার চেয়ে ত্রুটিপূর্ণ পরিসংখ্যান হলেও কিছু একটা থাকা ভালো।”
র্যাঙ্কিং বিষয়ক স্টোরিতে প্রেক্ষাপট সম্পর্কে সচেতন থাকা উচিত: কেবলমাত্র জনসংখ্যা বেশি হওয়ার কারণে কোনো এলাকায় অপরাধ, রোগ বা দূষণের পরিমাণ সবচেয়ে বেশি হতে পারে। প্রতিবেদনের তারিখের কারণেও বিভ্রান্তিকর ডেটা আসতে পারে: মঙ্গলবারে কোভিড আক্রান্তের হার শীর্ষে থাকে কারণ “সপ্তাহের ছুটির দিনগুলোতে অনেক মৃতের সংখ্যা জানানো হয় না,” যা ব্রিটিশ গণমাধ্যম সংস্থা ফুলফ্যাক্ট সামনে এনেছে।
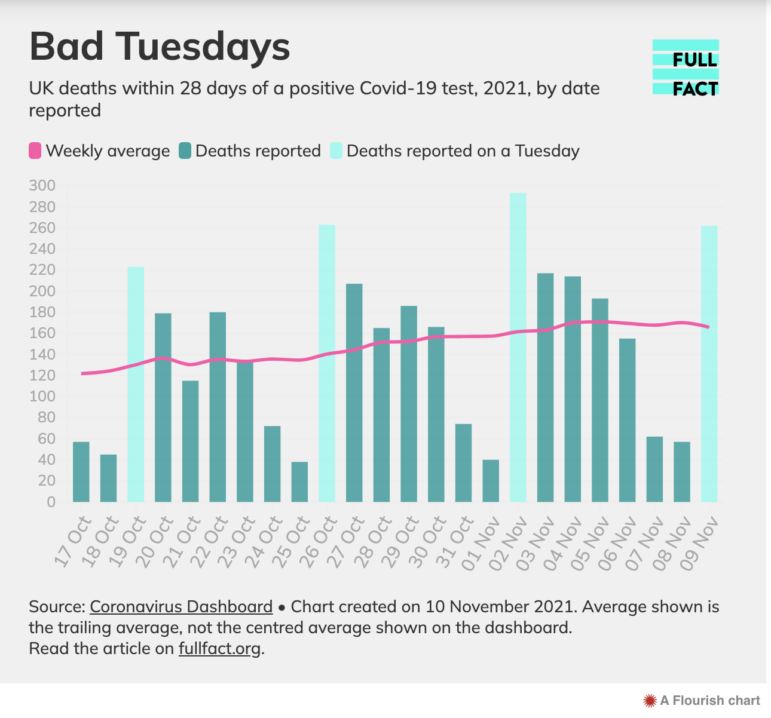
ছবি: স্ক্রিনশট, ফুলফ্যাক্টডটঅর্গ
ডেটা অ্যাঙ্গেল ৪: পার্থক্য — ‘পোস্টকোড লটারি,’ মানচিত্র ও বন্টন
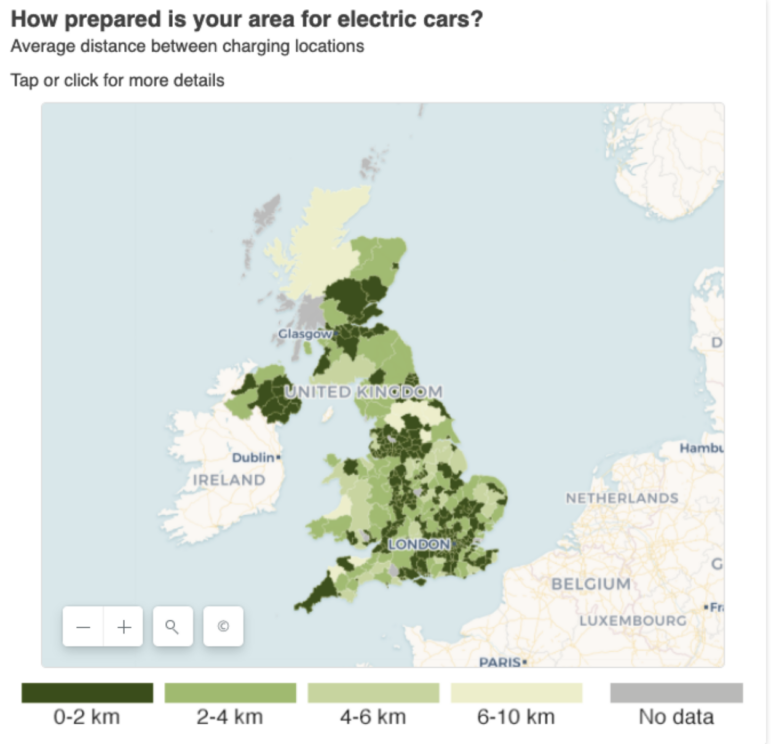
বিবিসির শেয়ার্ড ডেটা ইউনিটের হয়ে এইমি স্টানটনের এই স্টোরিটি বৈদ্যুতিক গাড়ির চার্জিং পয়েন্ট ব্যবহারের ক্ষেত্রে বিদ্যমান পার্থক্যের ওপর দৃষ্টিপাত করেছে। ছবি: স্ক্রিনশট, বিবিসি
আমরা যেখানে সমতাভিত্তিক আচরণ আশা করি বা জীবনের কোনো একটি পর্ব আঁতশ কাঁচের নিচে ফেলতে চাই, সেখানে পার্থক্য বা বৈষম্যের স্টোরিগুলো সবচেয়ে বেশি প্রযোজ্য।
কীভাবে একটি দেশের কিছু অংশের তুলনায় অন্য অংশে কোনো কিছু ব্যবহারের সুবিধা কম বা বেশি চাহিদা থাকে, তা দেখাতে কোরোপ্লেথ ম্যাপ বা হিটম্যাপের ব্যবহার একটি বহুল পরিচিত দৃষ্টান্ত।
যেমন, “পোস্টকোড লটারি” শব্দযুগল দিয়ে বোঝানো হয়, কোনো সুবিধা সবার সমানভাবে পাওয়ার কথা থাকলেও, তা আসলে কপালের ফের।
আইভিএফ: এনএইচএস কাপলস ‘ফেস সোশ্যাল রেশনিং,’ শীর্ষক বিবিসি ডেটা ইউনিটের স্টোরিতে যেমনটা উঠে আসে যে ইংল্যান্ডে আপনার অবস্থানের ভিত্তিতে কীভাবে সন্তান ধারণ সংশ্লিষ্ট চিকিৎসা সুবিধা পাওয়া বা না পাওয়া নির্ভর করে।
বৈষম্য বা পার্থক্য বিষয়ক স্টোরি হয়ত বিদ্যমান অন্যায্যতা – বা, মানুষ যদি তা আগে থেকে জেনে থাকে তবে তা কীভাবে ও কোথায় (বিশেষত তাদের এলাকায়) ঘটছে – সামনে আনে।
যান্ত্রিক বৈষম্য নিয়ে প্রোপাবলিকার এই ধারাবাহিকের মতো অ্যালগরিদম ভিত্তিক জবাবদিহিতার স্টোরিগুলোর বিষয়বস্তু অনেক সময় ভিন্নতা ও অন্যায্যতা হয়ে থাকে, কোনো অ্যালগরিদম বাছাই করা না হলে যা সামনে চলে আসে: বিশেষ কোনো পার্থক্য না থাকলেও কাউকে হয়তো ভিন্নভাবে সাজা দেওয়া হচ্ছে, বা ভিন্ন ধরনের বীমা সুবিধা দেওয়া হয়েছে।
অবহেলিত দাবি-দাওয়া বা সরবরাহ ঘাটতির বিষয়গুলোকে সমান গুরুত্ব দিয়ে তুলে ধরতে পার্থক্যসূচক স্টোরি ব্যবহার করা যেতে পারে: বিবিসি শেয়ার্ড ডেটা ইউনিটের হয়ে বৈদ্যুতিক গাড়ির চার্জিং পয়েন্ট নিয়ে আমার করা একটি কাজে দেশের বিদ্যমান অবকাঠামো পরিস্থিতি ও অবস্থান শনাক্ত করা হয়েছে। ডেটা থেকে যে চিত্র উঠে এসেছে, তা কেস স্টাডি ও পাল্টা ব্যবস্থা নেওয়ার ভিত্তি তৈরি করেছে।
এই ধারাবাহিকের দ্বিতীয় পর্বে আমি অন্য তিনটি অ্যাঙ্গেলে নজর দিয়েছি: অনুসন্ধানী স্টোরি; ডেটার গুণগত মান, অস্তিত্ব বা ঘাটতি; এবং সম্পর্ক বিষয়ক অ্যাঙ্গেল। ফিনিশ ভাষাতেও এই রেখচিত্রটি পাওয়া যায়।
আরও পড়ুন
ডেটা জার্নালিজম: দ্য জিআইজেএন কালেকশন
অনারিং দ্য বেস্ট ইন ডেটা জার্নালিজম: উইনার্স অব দ্য ২০২৩ সিগমা অ্যাওয়ার্ডস
হাও ডেটা জার্নালিস্টস ক্যান ইউজ অ্যানোনিমাইজেশন টু প্রোটেক্ট প্রাইভেসি
 পল ব্রাডশ, যুক্তরাজ্যের বার্মিংহাম সিটি বিশ্ববিদ্যালয়ে ডেটাসাংবাদিকতা এবং মাল্টিপ্লাটফর্ম ও মোবাইল সাংবাদিকতা বিষয়ে স্নাতকোত্তর কোর্স পরিচালনা করেন। তিনি বিবিসি ইংল্যান্ডের ডেটা ইউনিটেও পরামর্শক ডেটা সাংবাদিক হিসেবে কর্মরত আছেন।
পল ব্রাডশ, যুক্তরাজ্যের বার্মিংহাম সিটি বিশ্ববিদ্যালয়ে ডেটাসাংবাদিকতা এবং মাল্টিপ্লাটফর্ম ও মোবাইল সাংবাদিকতা বিষয়ে স্নাতকোত্তর কোর্স পরিচালনা করেন। তিনি বিবিসি ইংল্যান্ডের ডেটা ইউনিটেও পরামর্শক ডেটা সাংবাদিক হিসেবে কর্মরত আছেন।
