
ছবি: শাটারস্টক
প্রোপাবলিকার ক্রেইগ সিলভারম্যান ব্যাখ্যা করেছেন: কীভাবে একসঙ্গে অনেকগুলো পেজ আর্কাইভ করা যায়, পরিবর্তনের তুলনা করা যায় এবং দেখা যায়, কখন একটি পেজের বিভিন্ন উপাদান আর্কাইভ করা হয়েছে।
কীভাবে ওয়েব্যাক মেশিন সবচেয়ে ভালোভাবে ব্যবহার করা যায়– তা নিয়ে কিছু পরামর্শ ছিল ডিজিটাল ইনভেস্টিগেশনের আগের সংস্করণটিতে। ওয়েব্যাক মেশিনের পরিচালক, মার্ক গ্রাহামের একটি সাক্ষাৎকার নেওয়ার পর আমি এখানে হাজির হয়েছি আরও কিছু পরামর্শ নিয়ে।
তিনি সেখানে এমন কয়েকটি ফিচারের কথা বলেছেন, যেগুলো আমি উল্লেখ করতে ভুলে গিয়েছিলাম। আবার কয়েকটি ফিচার সম্পর্কে জানতামই না। আমরা সোশ্যাল মিডিয়া কন্টেন্ট আর্কাইভ করার চ্যালেঞ্জ নিয়েও কথা বলেছি।
ওয়েব্যাক মেশিন পরিচালনা করে ইন্টারনেট আর্কাইভ। ২৭ বছরের পুরোনো এই অলাভজনক প্রতিষ্ঠানটি কাজ করে সবার জন্য সব ধরনের জ্ঞানে প্রবেশাধিকার নিশ্চিত করতে। গ্রাহাম যেমনটি বলেছেন, “আমরা একটি ডিজিটাল লাইব্রেরি।”
তিনি বলেন, লাইব্রেরি হিসেবে প্রতিষ্ঠানটির ব্যবহারকারী নয়, বরং পৃষ্ঠপোষক আছে। সাংবাদিক ও গবেষক পৃষ্ঠপোষকদের জন্য প্রয়োজনীয় কিছু ফিচারে নজর দেয়া যাক।
১. পরিবর্তনগুলো দেখুন এবং তুলনা করুন
চেঞ্জ ফিচারটি ব্যবহার করে আপনি আর্কাইভ করা একই পেজের বিভিন্ন সংস্করণের মধ্যে তুলনা করতে পারবেন এবং পার্থক্যগুলো দেখতে পারবেন।
গ্রাহাম বলেছেন, “একজন সাংবাদিক হয়তো কোনো ওয়েবপেজের কন্টেন্ট সময়ের সঙ্গে কীভাবে পরিবর্তিত হয়েছে– তা নিয়ে একটি স্টোরি লিখছেন। সেক্ষেত্রে, তাঁকে ওয়েব্যাক মেশিনের চেঞ্জ ফিচার সম্পর্কে জানতে হবে। এখানে আপনি তুলনা করে দেখতে পারবেন যে, দুটি ভিন্ন সময়ে একটি ইউআরএল-এর উপাদানগুলো কীভাবে পরিবর্তন হয়েছে।”
ওয়েব্যাক মেশিনে যে আর্কাইভ পেজটি ব্রাউজ করছেন, তার ওপরের মেন্যুতে পাবেন এই চেঞ্জ ফিচার।

ছবি: স্ক্রিনশট
এই ইউআরএল ফরম্যাট থেকে আপনি সরাসরিও এটি লোড করতে পারেন:
https://web.archive.org/web/changes/https://www.nytco.com/journalism/
আপনি যে ইউআরএলটির পরিবর্তন তুলনা করতে চান, সেটি https://web.archive.org/web/changes/ এর পরে বসালেও একটি পেজ আসবে, যেখানে বছরভিত্তিক আর্কাইভ গ্রিডগুলো দেখা যাবে:
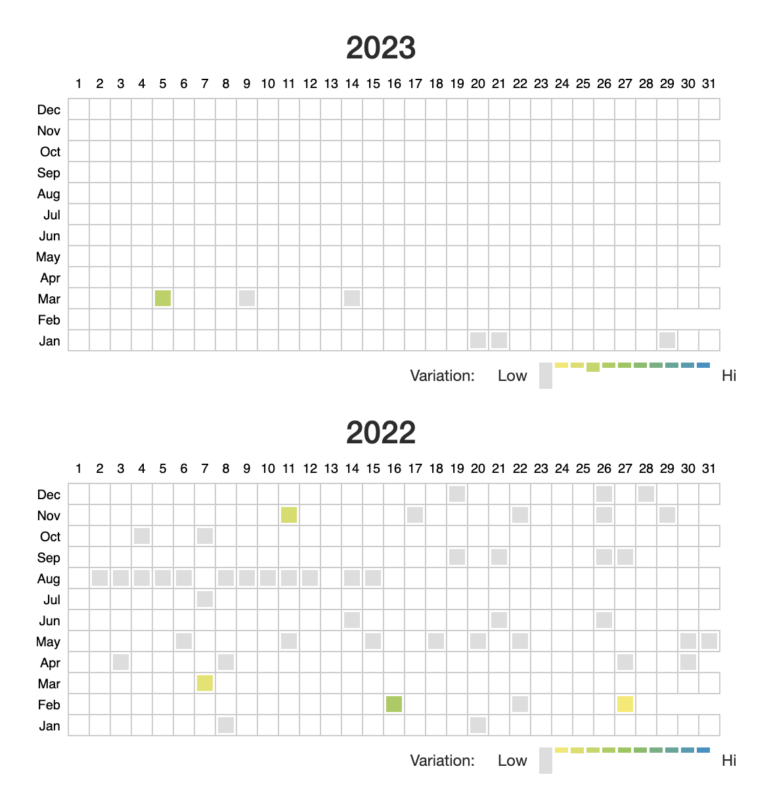
ছবি: স্ক্রিনশট, ওয়েব্যাক মেশিন
কোন দিনগুলোতে পেজটি আর্কাইভ করা হয়েছে– তা বোঝানো হয়েছে প্রতিটি ধূসর বর্গক্ষেত্র দিয়ে। এবং অন্যান্য রঙগুলো নির্দেশ করছে: কোন দিনগুলোতে পেজটিতে উল্লেখযোগ্য পরিবর্তন এসেছে। দুটি ক্যাপচার নির্বাচন করুন এবং পেজের উপরের দিকে “কম্পেয়ার” বাটনে ক্লিক করুন৷ এবার আপনি পাশাপাশি দুইটি ক্যাপচারের ভিউ পাবেন।
আমি ২০২৩ সালের মার্চের শুরুর দিকের একটি পেজ বেছে নিয়েছি (বামে) আর অন্যটি নিয়েছি ২০২২ সালের জানুয়ারি (ডানে) থেকে। তুলনায় দেখা যায়, নিজেদের সাংবাদিকতা নিয়ে নিউ ইয়র্ক টাইমসের কর্পোরেট পেজটির ফুটারে কিছু পরিবর্তন আনা হয়েছে।
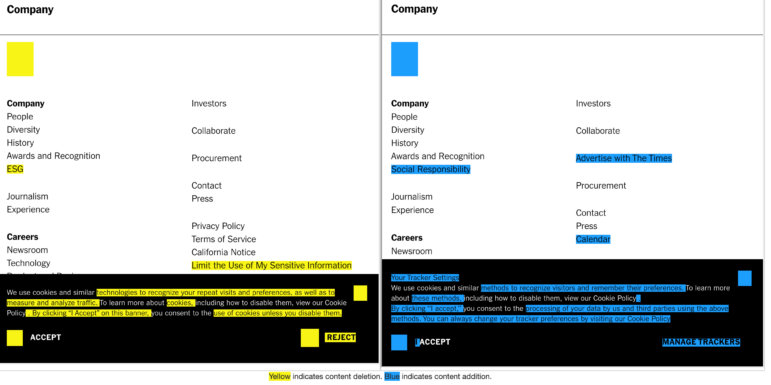
ছবি: স্ক্রিনশট, ওয়েব্যাক মেশিন
২. পেজের উপকরণ যাচাই করতে ‘অ্যাবাউট দিস ক্যাপচার’ ব্যবহার করুন
ওয়েব্যাক মেশিনের মূল বিষয় হলো, এটি ওয়েবপেজগুলো আর্কাইভ ও সংরক্ষণ করে। তবে বাস্তবে সেখানে আরও কিছু খুঁটিনাটি বিষয় থাকে।
গ্রাহাম বলেছেন, “ওয়েবের জগতটি অগোছালো, এবং এটি ক্রমাগত পরিবর্তিত হচ্ছে। আর আমি যখন ক্রমাগত পরিবর্তনের কথা বলি, তখন এটি গতিশীলও হতে পারে।”
আমি গ্রাহামের কাছে জানতে চেয়েছিলাম, নির্দিষ্ট দিন ও সময়ে ওয়েব্যাক মেশিনে আর্কাইভ করা একটি পেজের চেহারা কি হুবহু একই থাকে? এ নিয়ে আমরা কতটা আত্মবিশ্বাসী হতে পারি? সংক্ষেপে উত্তর হলো, হ্যাঁ, আপনি আস্থা রাখতে পারেন। তবে আর্কাইভ করা একটি পেজের উপাদানগুলো নেওয়া হয় আর্কাইভে থাকা বিভিন্ন উপকরণ থেকে। এবং প্রতিটিরই নিজস্ব টাইমস্ট্যাম্প থাকে। এখানেই আসে খুঁটিনাটি বিষয়গুলোর প্রসঙ্গ।
ওয়েব্যাক মেশিনের একটি ফিচার আছে, যেটি আপনাকে একটি পেজের বিভিন্ন উপাদানগুলোর টাইমস্ট্যাম্প দেখার সুযোগ করে দেয়। আপনি এটি দেখতে পারেন আর্কাইভ করা পেজটির উপরে ডান কোনায় থাকা “অ্যাবাউট দিস ক্যাপচার” বাটনে ক্লিক করে।
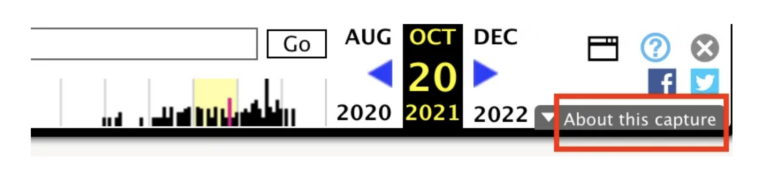
ছবি: স্ক্রিনশট
উদাহরণ হিসেবে https://www.nytco.com/journalism/ পেজটি ব্যবহার করে আমরা পেয়েছি এরকম কিছু:
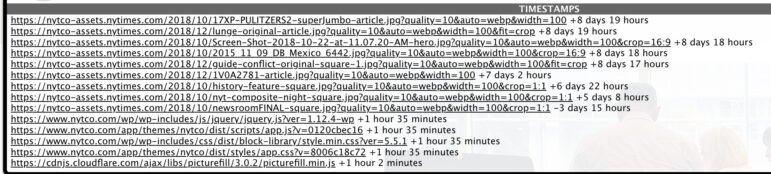
ছবি: স্ক্রিনশট, ওয়েব্যাক মেশিন
পেজটি ২০২১ সালের ২০ অক্টোবর আর্কাইভ করা হলেও, এটি আরও সাম্প্রতিক আর্কাইভ থেকে কিছু উপাদান টেনে এনেছে। উপরে থাকা বেশিরভাগ পেজ উপাদানই হলো ছবি, যেগুলো এই পেজ টেমপ্লেটটি তৈরি করেছে। কয়েকটি ফাইল আছে জাভাস্ক্রিপ্ট ও সিএসএস-এ। গ্রাহাম ব্যাখ্যা করে বলেন, আপনি পেজটি দেখতে চাইলে, ওয়েব্যাক মেশিন, বিভিন্ন ছবি, জাভাস্ক্রিপ্ট ও সিএসএস ফাইলগুলো এক জায়গায় এনে পেজটি তৈরি করে।
তিনি বলেছেন, “আমরা যখন কোনো পেজ সামনে আনি, তখন আর্কাইভে থাকা ইউআরএলটির বিভিন্ন পেজ উপাদান সংগ্রহ করি এবং সেগুলো এক জায়গায় এনে ব্যবহারকারীকে দেখাই। এর একটি চ্যালেঞ্জ হলো: এই পেজ উপাদানগুলো হয়তো আর্কাইভ করা হয়েছে ভিন্ন ভিন্ন সময়ে।”
যেমন, পেজের (“17XP-PULITZERS2-superJumbo-article.jpg”) উপরের দিকে মূল ছবিটি নেওয়া হয়েছে আমার এই পেজটি লোড করার ৮ দিন আগের একটি ক্যাপচার থেকে। এমন কোনো ছবি/ফাইল আপনার অনুসন্ধানের জন্য গুরুত্বপূর্ণ হলে সেটির আর্কাইভ পেজ যাচাই করুন এবং দেখুন এটি সময়ের সঙ্গে পরিবর্তিত হয়েছে কিনা বা দেখুন আপনার অনুসন্ধান সংশ্লিষ্ট সময়ের কাছাকাছি কোনো ক্যাপচার আছে কিনা। তবে ফাইলটি যদি সময়ের সঙ্গে পরিবর্তন না হয়, তাহলে আপনার ভাবনার কিছু নেই।
ছবি: স্ক্রিনশট, নিউ ইয়র্ক টাইমস কর্পোরেট ওয়েবসাইট
চূড়ান্ত না হলেও সাধারণ একটি নিয়ম হলো, ওয়েবপেজের মূল টেক্সটগুলো আলাদা কোনো পেজ বা ফাইল থেকে নেওয়া হয় না। তাই সেখানে পেজের অন্যান্য বিষয়াদির কোনো প্রভাব পড়ার সম্ভাবনা বেশি থাকে না। তবে সবচেয়ে নিরাপদ উপায় হলো “অ্যাবাউট দিস ক্যাপচার” দেখে নেওয়া এবং নিশ্চিত করা যে, পেজ ক্যাপচারে আপনি যে টেক্সট, ছবি বা অন্যান্য উপকরণ উল্লেখ করছেন, তা আপনার পছন্দের তারিখের সঙ্গে সামঞ্জস্যপূর্ণ।
৩. গুগল শিট ব্যবহার করে একসঙ্গে অনেক লিংক আর্কাইভ করুন
গ্রাহাম আমাকে মনে করিয়ে দিয়েছেন যে, গুগল শিট ব্যবহার করে আপনি একসঙ্গে অনেকগুলো ইউআরএল আর্কাইভ করতে পারেন। প্রক্রিয়াটি বেশ সহজ। প্রথমে আপনি যে ইউআরএলগুলো আর্কাইভ করতে চান, সেগুলো গুগল শিটের একটি কলামে রাখুন। এরপর এখানে গিয়ে আপনার গুগল অ্যাকাউন্টের সঙ্গে আর্কাইভ অ্যাকাউন্টটি যুক্ত করুন।

ছবি: স্ক্রিনশট, ইন্টারনেট আর্কাইভ
একবার এটি হলে গেলে আপনি এই স্ক্রিনটি দেখতে পাবেন। এখানে “আর্কাইভ ইউআরএল”-এ ক্লিক করুন।

ছবি: স্ক্রিনশট, ইন্টারনেট আর্কাইভ
এবার আপনি যে গুগল শিটে ইউআরএলগুলো রেখেছেন, সেটির লিংক এখানে যোগ করুন।
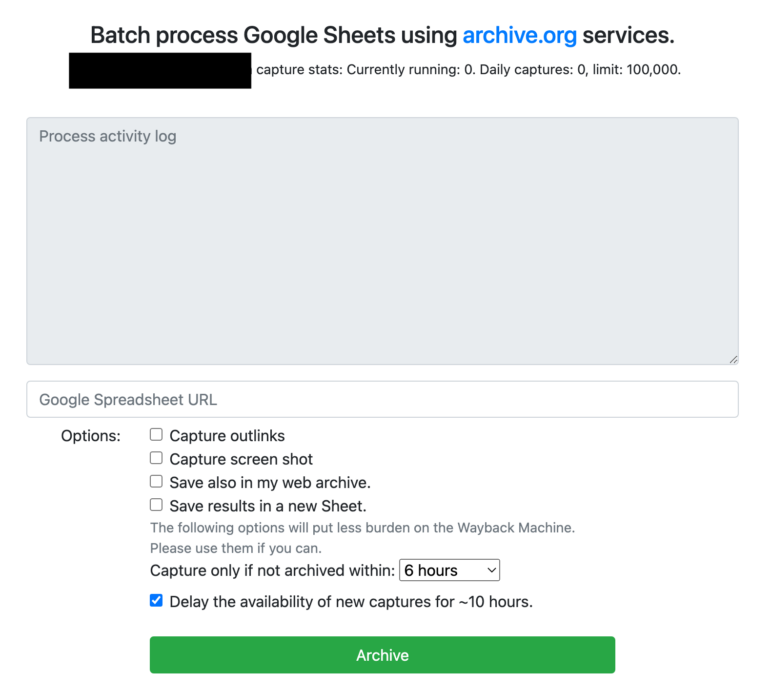
ছবি: স্ক্রিনশট, ইন্টারনেট আর্কাইভ
গুগল ও আর্কাইভ অ্যাকাউন্ট একে অপরের সঙ্গে যুক্ত থাকায়, আপনার সব ক্যাপচারগুলো জমা হবে আর্কাইভ অ্যাকাউন্টে। এবং সেগুলো আপনি সহজেই দেখে নিতে পারবেন।
গ্রাহাম বলেছেন, “এই ফিচারটি যুক্ত হয়েছে, কারণ আমার স্ত্রী একদিন আমাকে প্রশ্ন করেছিলেন, ‘মার্ক, আমি কীভাবে অনেকগুলো ইউআরএল সহজে আর্কাইভ করতে পারি?’”
পরে ইন্টারনেট আর্কাইভের প্রকৌশলীদের সঙ্গে কাজ করে এটি তৈরি করেছিলেন গ্রাহাম।
৪. আপনার মতামত ও অনুরোধ ইমেইল করুন
গ্রাহাম বলেছেন, “ওয়েব্যাক মেশিনের এমন অনেক অনেক ফিচার আছে কারণ কোনো পৃষ্ঠপোষক হয়তো সেগুলো সম্পর্কে জানতে চেয়েছিলেন, বা কোনো পরামর্শ বা সুপারিশ দিয়েছিলেন। আমরা সত্যিই এমন অনুরোধ ও প্রশ্নকে স্বাগত জানাই।”
তিনি মানুষকে info@archive.org -এ ইমেইল করতে উৎসাহ দেন।
গ্রাহাম বলেন, “আমরা প্রতিদিন শত শত ইমেইল পাই আর আমাদের একটি দল সেগুলো পর্যালোচনা করে ও উত্তর দেয়। আমি ব্যক্তিগতভাবে ওয়েব্যাক মেশিন সম্পর্কিত সেসব প্রশ্নের উত্তর দেই, যেগুলোর ক্ষেত্রে প্রাথমিক পর্যায়ের উত্তর যথেষ্ট নয়।”
তিনি বিশেষভাবে সাংবাদিকদের কোনো প্রশ্ন বা অনুরোধ থাকলে যোগাযোগের জন্য উৎসাহিত করেছেন।
উপরি তথ্য: সোশ্যাল মিডিয়া আর্কাইভ করা
ওয়েব্যাক মেশিনের দক্ষ ব্যবহারকারীরা জানেন যে, সোশ্যাল মিডিয়ার কন্টেন্ট আর্কাইভ করা খুবই কঠিন বা অসম্ভব। তবে এর সঙ্গে ওয়েব্যাক মেশিনের ফাংশন ও সীমাবদ্ধতার সম্পর্ক কমই আছে। বরং অনেক বেশি সংযোগ আছে মেটার মতো কোম্পানিগুলোর, যারা স্ক্র্যাপিং আটকানোর চেষ্টা করে।
সোশ্যাল মিডিয়ার কন্টেন্ট আর্কাইভ করা কেন কঠিন, তা নিয়ে গ্রাহামের বক্তব্য এরকম:
অন্যান্য ওয়েবসাইটের তুলনায় কিছু ওয়েবসাইট আর্কাইভ করা বেশি চ্যালেঞ্জিং, বিশেষ করে ফেসবুক ও ইনস্টাগ্রামের ক্ষেত্রে এটি বোঝা যায়। তারা বিভিন্ন ধরনের অটোমেশন আটকানোর জন্য সক্রিয় পদক্ষেপ নিয়েছে, যার মধ্যে স্ক্র্যাপিংও আছে। ফেসবুকের সাইটে স্ক্র্যাপিং নিয়ে একটা আলাদা সেকশন আছে, যেখানে তারা কথা বলেছে ওয়েব স্ক্র্যাপিং ও আর্কাইভিংয়ের চেষ্টা রুখে দেওয়ার জন্য তাদের নিবেদিত কর্মীদের নিয়ে।
আমরা ওয়েব নিয়ে কাজ করি সম্মানের সঙ্গে। এগুলো আমাদের বানানো জিনিস না। লাইব্রেরি হিসেবে আমরা কাজ করি সাধারণভাবে এগুলো সবার জন্য উন্মুক্ত রাখতে। ফেসবুক ও ইনস্টাগ্রামের ক্ষেত্রেও আমরা সেই চেষ্টা করেছি। এবং আমরা মনে করি, সবার জন্য উন্মুক্ত– এমন তথ্য আর্কাইভ করা আমাদের জন্যও পুরোপুরি যুক্তিসঙ্গত। যেমন, এটি হতে পারত ইউক্রেন বা চীনের যোগাযোগ বিভাগের পাবলিক ফেসবুক পেজ।
উৎসাহ জোগানোর মতো খবরগুলোর একটি হলো, গ্রাহাম বলেছেন, সোশ্যাল মিডিয়া আর্কাইভের চেষ্টা ও উন্নতির জন্য ওয়েব্যাক মেশিন “বেশ কয়েকটি গণমাধ্যম সংস্থার সঙ্গে সক্রিয়ভাবে কাজ করছে।” আশা করি, দ্রুতই পরিস্থিতির উন্নতি হবে।
পোস্টটি প্রথম প্রকাশিত হয়েছিল ক্রেইগ সিলভারম্যানের ডিজিটাল ইনভেস্টিগেশন্স সাবস্ট্যাক নিউজলেটারে। অনুমতি নিয়ে এখানে পুনরায় প্রকাশ করা হলো।
আরও পড়ুন
অনলাইনে ভুয়া তথ্য, ভুয়া খবর ও ভুয়া পণ্যের বেচাকেনা যে টুল দিয়ে অনুসন্ধান করেন ক্রেইগ সিলভারম্যান
সাংবাদিকদের জীবনকে সহজ করবে যে ৫টি অনলাইন সার্চ টুল
আপনার পরবর্তী অনুসন্ধানে ওয়েব্যাক মেশিন ব্যবহার করবেন যেভাবে
 ক্রেইগ সিলভারম্যান প্রোপাবলিকার জাতীয় প্রতিবেদক। তিনি ভোটিং, প্ল্যাটফর্ম, ডিসইনফর্মেশন, এবং অনলাইন জালিয়াতি নিয়ে কাজ করেন। তিনি আগে বাজফিড নিউজের গণমাধ্যম সম্পাদক ছিলেন। এখানে তিনি ডিজিটাল ডিসইনফর্মেশন সংক্রান্ত কভারেজের পথ প্রদর্শক ছিলেন।
ক্রেইগ সিলভারম্যান প্রোপাবলিকার জাতীয় প্রতিবেদক। তিনি ভোটিং, প্ল্যাটফর্ম, ডিসইনফর্মেশন, এবং অনলাইন জালিয়াতি নিয়ে কাজ করেন। তিনি আগে বাজফিড নিউজের গণমাধ্যম সম্পাদক ছিলেন। এখানে তিনি ডিজিটাল ডিসইনফর্মেশন সংক্রান্ত কভারেজের পথ প্রদর্শক ছিলেন।

{kind=link}