The Chicago Reporter was a few days from publishing a major investigation into lawsuits against Chicago police when we learned we needed to revise a number in our story.

Screenshot of Chicago Reporter’s “Settling for Misconduct” investigation
A city bond issue, used to pay for two years of settlements and judgments of police misconduct, would end up costing Chicagoans $530 million after interest payments—a number higher than we previously thought.
Our conclusion? “We’re gonna need a bigger chart.” Five hundred and thirty million wouldn’t fit the Y-axis of our bar graph.
It was a fitting wrap to the years-long project, which, in a lot of ways, seemed outsized for a six-person nonprofit newsroom.
In researching Settling for Misconduct, we had to account for details from hundreds of county and federal court filings, identify thousands of officers named in civil complaints and tally hundreds of millions of dollars in monetary awards.
We also needed thorough reporting to connect issues of police misconduct to fiscal accountability.
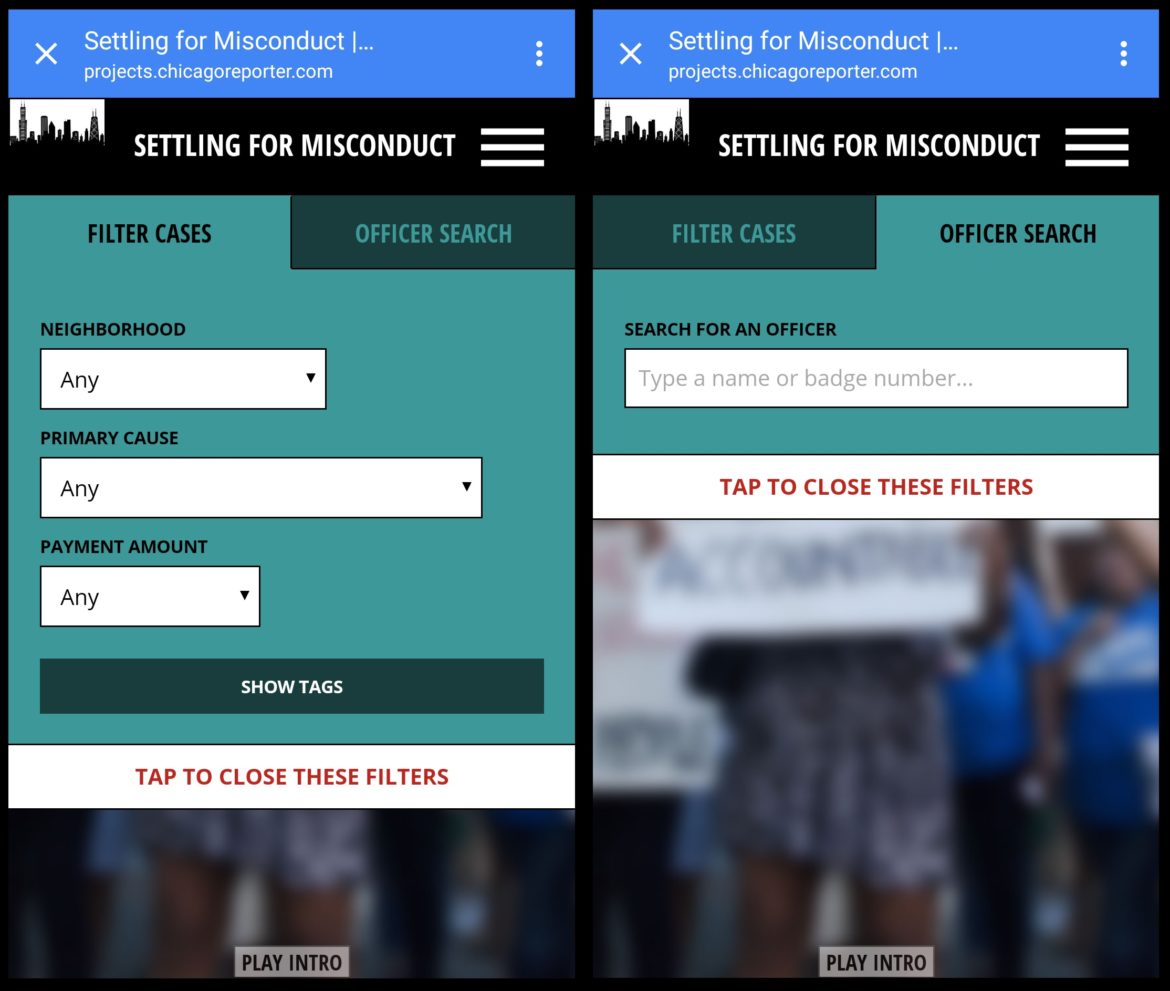 And oh yeah—we had to have a slick web app to present the data to the public. (We hired the good folks at the Institute for Nonprofit News to build it—more on that later.)
And oh yeah—we had to have a slick web app to present the data to the public. (We hired the good folks at the Institute for Nonprofit News to build it—more on that later.)
We couldn’t turn this one around on a typical project schedule. We couldn’t even do it all by ourselves. We would need outside help, more staff, and a big leap to try something completely new and different.
Here’s how we did it.
Research
The idea here was to build on a 2012 investigation that focused on Chicago police officers sued in multiple lawsuits. Publishing complaint summaries, defendants, and settlement amounts would help the public hold its police force and elected officials accountable for officer misconduct.
This project was a natural fit for the Reporter, which has taken a data-driven approach to investigating race and poverty in Chicago since the publication’s founding in 1972. We suspected—and data later demonstrated—that police misconduct cases disproportionately occurred in neighborhoods that are majority black or Hispanic.
 Early in the research process, tracking down the cases proved to be the easy part. The city Law Department posts lists of payments made as a result of judgment and settlements. Narrowing the list down to police misconduct lawsuits between 2012 and 2015, we had about 655 case numbers that we could use to look up complaints and other files.
Early in the research process, tracking down the cases proved to be the easy part. The city Law Department posts lists of payments made as a result of judgment and settlements. Narrowing the list down to police misconduct lawsuits between 2012 and 2015, we had about 655 case numbers that we could use to look up complaints and other files.
With a grant from the Open Society Foundations, we contracted three researchers to read through each case file and key data into various tables: cases, cops, victims, payments.
This is a good place to highlight the benefits of database normalization. Since each complaint could have multiple plaintiffs, name multiple officers, and result in multiple payments, we divided the data in separate tables and linked them to each other to avoid typing redundant information. This was a big time saver and, more importantly, helped us ensure consistency and accuracy.
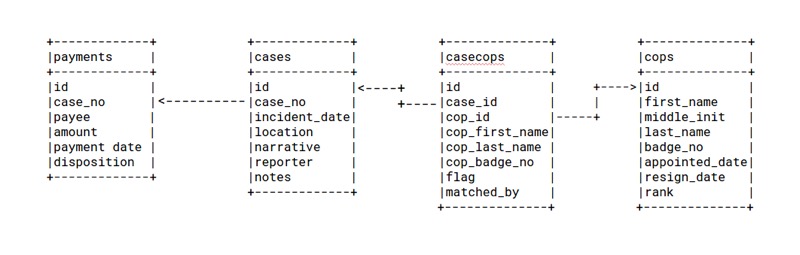
Finally, we had to specifically identify the officers named in the complaints in order to track the cases they were named in, along with the resulting payments. This was tricky because legal complaints often have partial or misspelled names and may or may not include badge numbers.
The Reporter could have tried to derive a standardized list of police officers from the inconsistent list of defendants—the sort of thing you may recognize if, say, you’ve ever used OpenRefine. This would not have worked for us for a variety of reasons: We had to key off of first, last, and middle names or combinations thereof; police officers could have many badge numbers over the course of their career; and we wanted to account for dates of service.
So we took another approach: The Reporter FOIA’d a complete list of police officers from the Chicago Police Department, going back several decades. We loaded the data into a Django object-relational mapper and wrote some algorithms to derive a match for each named defendant based on their names (first, last, and middle), badge numbers and dates of service. If the algorithms could identify a defendant with a high degree of certainty, it established a foreign-key relationship to the cops table.
We were able to automate 85 percent of the matches, and we built a neat web interface for humans to figure out the rest. We didn’t change any source data and audited every database update we made so that we could go back and manually verify every relationship we established.
We published our cop-matcher on GitHub in case other journalists or researchers would like to check it out.
Development
As the Reporter was working to match officers to lawsuits and finalize database structure, the INN technology team was busy building a standalone news app to bring the data to the public.
The app we developed has two parts—an introductory storytelling page to showcase the Reporter’s photography and key findings from the investigation, and the main application that allows users to filter the 655 lawsuits by various fields and search for individual officers by name or badge number.
Our initial focus was on the more complicated piece—the standalone app—and we kept a few goals in mind as we were designing it. We hoped to:
- Show how much the city has paid in settlements in police misconduct cases.
- Make it simple for users to identify who was involved and the allegations in each case.
- Allow people to easily engage with and share this information.
- Make sure the process to update the data is simple and straightforward.
We worked with the Reporter’s team to finalize wireframes, and while the visual design was in progress, we began developing our own JSON schema and back-end processes for the app.
We used Tarbell, the Chicago Tribune’s static site generator, to quickly get up and running. Tarbell provides easy content management thanks to its simple Google Sheets integration, and it has a built-in publishing workflow that pushes pre-baked files to Amazon S3. We decided to go with Backbone as our data-binding framework for the front end.
There were a couple fun technical problems to solve during the development process. The first was that we wanted users to be able to filter lawsuits by neighborhood rather than a specific address so it would be easier for them to identify incidents of police misconduct that happened near their home or place of work. None of the existing data had a “neighborhood” field, so Ryan Nagle, the lead developer on this project, wrote a custom script based on the Tribune’s Django Boundary Service that matches individual addresses with neighborhoods and community areas as defined by the City of Chicago’s GIS program.

Another challenging piece was the Mad-Lib style search result area, which required a complicated Underscore template to ensure the grammar and punctuation was correct for every combination of search selections.
We started developing this feature by simply writing sentences. The first step was to compose a basic sentence that would describe every possible result:
Example: “A case resulted from an incident.”
The next step was to take that sentence and add to it all of the possible fields a user could select: neighborhood, primary cause, payment amount, and a bunch of tags. Using the example above and keeping the fields in the order they appear in the UI, our first full sentence was something like:
“One case in South Deering resulted from an incident of excessive force that cost Chicago $0-$3000 and was tagged traffic stop and false report.”
That wasn’t especially clear or easy to understand. Nor was it flexible. We needed to rearrange the fields so that the tags and payment amount described the case, and the primary cause and neighborhood described the incident. We also had to account for different numbers of results and adjust the wording accordingly. After we were happy with the flexibility of the full sentence configuration, we started removing selections one at a time and adjusting the logic in the template so the sentence format continued to make sense.
There is surely a more programmatic way to have approached this problem, but in this case we primarily relied on human testing to make sure the sentence structure felt appropriate in as many use cases as possible.
Launch
The Reporter published the full Settling for Misconduct series in June, and we continue to collect data on police misconduct in Chicago. Our long-term goal is for this app to be a source of information for a broad group of Chicagoans as well as journalists, advocates and others around the country and the world who are interested in policing issues.
This article first appeared on Source, an Open News website and is cross-posted here with permission.
 Matt Kiefer is data editor for The Chicago Reporter, a nonprofit paper that’s been “investigating race and poverty since 1972.” He was previously an FOIA researcher at the Better Government Association, another Chicago-based nonprofit that was among the pioneers in using investigative techniques to expose lack of accountability.
Matt Kiefer is data editor for The Chicago Reporter, a nonprofit paper that’s been “investigating race and poverty since 1972.” He was previously an FOIA researcher at the Better Government Association, another Chicago-based nonprofit that was among the pioneers in using investigative techniques to expose lack of accountability.
 Julia Smith is the Design Lead for the Institute for Nonprofit News, where she produces custom editorial projects for INN’s member organizations and helps support Largo, an open-source WordPress framework for news websites. Previously, Julia was a 2015 Knight-Mozilla Fellow with the Center for Investigative Reporting.
Julia Smith is the Design Lead for the Institute for Nonprofit News, where she produces custom editorial projects for INN’s member organizations and helps support Largo, an open-source WordPress framework for news websites. Previously, Julia was a 2015 Knight-Mozilla Fellow with the Center for Investigative Reporting.

What does the average home owner citizen in Chicago pay in taxes for its police protection and police misconduct